
在RTX5090上,按照 https://github.com/openai/gpt-oss 的说明进行安装后,直接运行会出现以下错误:
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/gpt_oss/chat.py", line 369, in <module>
main(args)
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/gpt_oss/chat.py", line 67, in main
generator = TritonGenerator(args.checkpoint, args.context, device)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/torch/utils/_contextlib.py", line 120, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/gpt_oss/triton/model.py", line 478, in __init__
self.model(self.input_token[None, :], caches=self.caches)
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1773, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1784, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/gpt_oss/triton/model.py", line 413, in forward
x = block(x, cache=cache)
^^^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1773, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1784, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/gpt_oss/triton/model.py", line 377, in forward
x = self.mlp(x)
^^^^^^^^^^^
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1773, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/torch/nn/modules/module.py", line 1784, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/contextlib.py", line 81, in inner
return func(*args, **kwds)
^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/gpt_oss/triton/model.py", line 346, in forward
t = moe(
^^^^
File "/home/wyy/gpt-oss/.venv/lib/python3.12/site-packages/gpt_oss/triton/moe.py", line 51, in moe
x = matmul_ogs(x, w1, b1, rdata, gather_indx=gather_indx, precision_config=pc1, fused_activation=act)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/triton/python/triton_kernels/triton_kernels/matmul_ogs.py", line 467, in matmul_ogs
(kernels._p_matmul_ogs if opt_flags.is_persistent else kernels._matmul_ogs)[(grid,)](
File "/home/wyy/gpt-oss/triton/python/triton/runtime/jit.py", line 419, in <lambda>
return lambda *args, **kwargs: self.run(grid=grid, warmup=False, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/triton/python/triton/runtime/jit.py", line 756, in run
launch_metadata = kernel.launch_metadata(grid, stream, *bound_args.values())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/wyy/gpt-oss/triton/python/triton/compiler/compiler.py", line 483, in launch_metadata
self._init_handles()
File "/home/wyy/gpt-oss/triton/python/triton/compiler/compiler.py", line 457, in _init_handles
raise_(OutOfResources(self.metadata.shared, max_shared, "shared memory"))
File "/home/wyy/gpt-oss/triton/python/triton/compiler/compiler.py", line 449, in raise_
raise err
triton.runtime.errors.OutOfResources: out of resource: shared memory, Required: 131072, Hardware limit: 101376. Reducing block sizes or `num_stages` may help.这是由于每个SM的缓存大小不足,所以无法运行。需要修改默认的`num_stages`来减少显存使用。
方法一(使用我修改好的仓库):
为了方便使用,我创建了一个新的Fork,修复了5090的显存溢出问题
https://github.com/echo-cool/gpt-oss#
可以直接运行以下命令克隆此仓库,并按照说明安装相关依赖
git clone https://github.com/echo-cool/gpt-oss#
cd gpt-oss
pip install gpt-oss[triton]
# gpt-oss-20b
hf download openai/gpt-oss-20b --include "original/*" --local-dir gpt-oss-20b/
git clone https://github.com/triton-lang/triton
cd triton/
pip install -r python/requirements.txt
pip install -e . --verbose --no-build-isolation
pip install -e python/triton_kernels
# Install the gpt-oss triton implementation
pip install -e ".[triton]"
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
# run chat
python -m gpt_oss.chat gpt-oss-20b/original/方法二(手动修改):
下面一个修改好的model.py文件,经过测试可以在5090上正常运行
import json
import math
import os
import torch
from torch.profiler import record_function
from gpt_oss.torch.model import ModelConfig, RMSNorm
from gpt_oss.torch.weights import Checkpoint
from gpt_oss.triton.attention import attention, attention_ref
from gpt_oss.triton.moe import quantize_mx4, moe
# Import optimization constraint function for fixing shared memory issues
try:
from triton_kernels.matmul_ogs_details.opt_flags import update_opt_flags_constraints
except ImportError:
update_opt_flags_constraints = None
class RotaryEmbedding(torch.nn.Module):
def __init__(
self,
head_dim: int,
base: int,
dtype: torch.dtype,
initial_context_length: int = 4096,
max_context_length: int = 131072,
scaling_factor: float = 1.0,
ntk_alpha: float = 1.0,
ntk_beta: float = 32.0,
device: torch.device | None = None,
) -> None:
super().__init__()
self.head_dim = head_dim
self.base = base
self.dtype = dtype
self.initial_context_length = initial_context_length
self.max_context_length = max_context_length
self.scaling_factor = scaling_factor
self.ntk_alpha = ntk_alpha
self.ntk_beta = ntk_beta
self.device = device
self.cos, self.sin = self._compute_cos_sin(0, self.max_context_length)
def _compute_concentration_and_inv_freq(self) -> torch.Tensor:
"""See YaRN paper: https://arxiv.org/abs/2309.00071"""
freq = self.base ** (
torch.arange(0, self.head_dim, 2, dtype=torch.float, device=self.device)
/ self.head_dim
)
if self.scaling_factor > 1.0:
concentration = (
0.1 * math.log(self.scaling_factor) + 1.0
) # YaRN concentration
d_half = self.head_dim / 2
# NTK by parts
low = (
d_half
* math.log(self.initial_context_length / (self.ntk_beta * 2 * math.pi))
/ math.log(self.base)
)
high = (
d_half
* math.log(self.initial_context_length / (self.ntk_alpha * 2 * math.pi))
/ math.log(self.base)
)
assert 0 < low < high < d_half - 1
interpolation = 1.0 / (self.scaling_factor * freq)
extrapolation = 1.0 / freq
ramp = (
torch.arange(d_half, dtype=torch.float32, device=freq.device) - low
) / (high - low)
mask = 1 - ramp.clamp(0, 1)
inv_freq = interpolation * (1 - mask) + extrapolation * mask
else:
concentration = 1.0
inv_freq = 1.0 / freq
return concentration, inv_freq
def _compute_cos_sin(self, start: int, num_tokens: int):
concentration, inv_freq = self._compute_concentration_and_inv_freq()
t = torch.arange(start, start + num_tokens, dtype=torch.float32, device=self.device)
freqs = torch.einsum("i,j->ij", t, inv_freq)
cos = freqs.cos() * concentration
sin = freqs.sin() * concentration
return cos, sin
@record_function("rotate")
def _rotate(
self,
x: torch.Tensor,
cos: torch.Tensor,
sin: torch.Tensor,
) -> torch.Tensor:
cos = cos[None, :, None, :].to(x.dtype)
sin = sin[None, :, None, :].to(x.dtype)
x1, x2 = torch.chunk(x, 2, dim=-1)
o1 = x1 * cos - x2 * sin
o2 = x2 * cos + x1 * sin
return torch.cat((o1, o2), dim=-1)
@record_function("rope")
def forward(
self,
query: torch.Tensor,
key: torch.Tensor,
offset: torch.LongTensor,
) -> tuple[torch.Tensor, torch.Tensor]:
batch_size, num_tokens, num_heads, head_dim = query.shape
batch_size, num_tokens, num_key_value_heads, head_dim = key.shape
idx = torch.arange(num_tokens, device=query.device, dtype=torch.long) + offset
idx = idx % self.max_context_length
cos = self.cos.index_select(0, idx)
sin = self.sin.index_select(0, idx)
query = self._rotate(query, cos, sin)
key = self._rotate(key, cos, sin)
return query, key
class Cache:
def __init__(self, batch_size, n_ctx, n_kv_heads, d_head=64, device: torch.device | None = None):
self.k = torch.zeros((batch_size, n_ctx, n_kv_heads, d_head), dtype=torch.bfloat16, device=device)
self.v = torch.zeros((batch_size, n_ctx, n_kv_heads, d_head), dtype=torch.bfloat16, device=device)
self.offset = torch.zeros((1,), dtype=torch.long, device=device)
def reset(self):
self.k.zero_()
self.v.zero_()
self.offset.zero_()
def repeat_interleave(self, n):
"""Repeat each cache entry n times along the batch dimension."""
self.k = self.k.repeat_interleave(n, dim=0)
self.v = self.v.repeat_interleave(n, dim=0)
def truncate(self, n_ctx):
"""Truncate the cache to the first n_ctx tokens."""
batch_size, _, n_kv_heads, d_head = self.k.shape
assert batch_size == self.v.shape[0]
assert n_ctx <= self.k.shape[1]
self.k[:, n_ctx:, :, :].zero_()
self.v[:, n_ctx:, :, :].zero_()
self.offset.fill_(n_ctx)
return self.k, self.v
def extend(self, k, v):
batch_size, n_ctx, *_rest = k.shape
assert batch_size == self.k.shape[0]
indices = torch.arange(0, n_ctx, device=k.device, dtype=torch.long) + self.offset
self.k.index_copy_(1, indices, k)
self.v.index_copy_(1, indices, v)
self.offset.add_(n_ctx)
return self.k, self.v
class AttentionBlock(torch.nn.Module):
def __init__(
self,
config: ModelConfig,
layer_idx: int = 0,
device: torch.device | None = None,
):
super().__init__()
self.head_dim = config.head_dim
self.num_attention_heads = config.num_attention_heads
self.num_key_value_heads = config.num_key_value_heads
# Only apply sliding window to every other layer
self.sliding_window = config.sliding_window if layer_idx % 2 == 0 else 0
self.layer_idx = layer_idx
self.sinks = torch.nn.Parameter(
torch.empty(config.num_attention_heads, device=device, dtype=torch.bfloat16)
)
self.norm = RMSNorm(config.hidden_size, device=device)
qkv_dim = config.head_dim * (
config.num_attention_heads + 2 * config.num_key_value_heads
)
self.qkv = torch.nn.Linear(
config.hidden_size, qkv_dim, device=device, dtype=torch.bfloat16
)
self.out = torch.nn.Linear(
config.head_dim * config.num_attention_heads,
config.hidden_size,
device=device,
dtype=torch.bfloat16,
)
self.sm_scale = 1 / math.sqrt(config.head_dim)
self.rope = RotaryEmbedding(
config.head_dim,
config.rope_theta,
torch.float32,
initial_context_length=config.initial_context_length,
scaling_factor=config.rope_scaling_factor,
ntk_alpha=config.rope_ntk_alpha,
ntk_beta=config.rope_ntk_beta,
device=device,
)
@record_function("attn")
def forward(self, x: torch.Tensor, cache: Cache | None = None) -> torch.Tensor:
batch_size, n_ctx, dim = x.shape
t = self.norm(x)
with record_function("qkv"):
qkv = self.qkv(t)
qkv_parts = (
self.num_attention_heads * self.head_dim,
self.num_key_value_heads * self.head_dim,
self.num_key_value_heads * self.head_dim
)
q, k, v = torch.split(qkv, qkv_parts, dim=-1)
q, k, v = q.contiguous(), k.contiguous(), v.contiguous()
q = q.view(batch_size, n_ctx, self.num_attention_heads, self.head_dim)
k = k.view(batch_size, n_ctx, self.num_key_value_heads, self.head_dim)
v = v.view(batch_size, n_ctx, self.num_key_value_heads, self.head_dim)
if cache is not None:
offset = cache.offset.clone()
q, k = self.rope(q, k, offset=offset)
k, v = cache.extend(k, v)
else:
offset = torch.zeros((1,), dtype=torch.long, device=x.device)
q, k = self.rope(q, k, offset=offset)
q = q.view(
batch_size,
n_ctx,
self.num_attention_heads // self.num_key_value_heads,
self.num_key_value_heads,
self.head_dim,
)
with record_function("attn_kernel"):
if n_ctx == 1:
t = attention_ref(
q,
k,
v,
self.sinks,
self.sm_scale,
self.sliding_window,
offset,
)
else:
t = attention(
q,
k,
v,
self.sinks,
self.sm_scale,
self.sliding_window,
offset,
)
if n_ctx < 64:
t1 = attention_ref(
q,
k,
v,
self.sinks,
self.sm_scale,
self.sliding_window,
offset,
)
torch.testing.assert_close(t, t1)
t = t1
with record_function("c_proj"):
t = self.out(t)
t = x + t
return t
class MLPBlock(torch.nn.Module):
def __init__(
self,
config: ModelConfig,
layer_idx: int = 0,
device: torch.device | None = None,
):
super().__init__()
self.layer_idx = layer_idx
self.num_experts = config.num_experts
self.experts_per_token = config.experts_per_token
self.swiglu_limit = config.swiglu_limit
self.norm = RMSNorm(config.hidden_size, device=device)
self.gate = torch.nn.ParameterDict({
"weight": torch.nn.Parameter(
torch.empty(
(config.hidden_size, config.num_experts),
device=device,
dtype=torch.bfloat16,
)
),
"bias": torch.nn.Parameter(
torch.empty(
(config.num_experts,),
device=device,
dtype=torch.bfloat16,
)
),
})
self.mlp1_weight_tensor, self.mlp1_weight_mx = quantize_mx4(
torch.empty(
(
config.num_experts,
config.hidden_size,
config.intermediate_size * 2,
),
device=device,
dtype=torch.bfloat16,
),
)
self.mlp1_weight = torch.nn.Parameter(self.mlp1_weight_tensor.storage.data, requires_grad=False)
self.mlp1_bias = torch.nn.Parameter(
torch.empty(
(config.num_experts, config.intermediate_size * 2),
device=device,
dtype=torch.bfloat16,
)
)
self.mlp2_weight_tensor, self.mlp2_weight_mx = quantize_mx4(
torch.empty(
(
config.num_experts,
config.intermediate_size,
config.hidden_size,
),
device=device,
dtype=torch.bfloat16,
),
)
self.mlp2_weight = torch.nn.Parameter(self.mlp2_weight_tensor.storage.data, requires_grad=False)
self.mlp2_bias = torch.nn.Parameter(
torch.empty(
(config.num_experts, config.hidden_size),
device=device,
dtype=torch.bfloat16,
)
)
@record_function("mlp")
def forward(self, x: torch.Tensor) -> torch.Tensor:
batch_size, n_ctx, dim = x.shape
t = self.norm(x)
t = t.view(batch_size * n_ctx, dim)
t = moe(
t,
self.gate["weight"],
self.mlp1_weight_tensor, self.mlp1_weight_mx,
self.mlp2_weight_tensor, self.mlp2_weight_mx,
self.gate["bias"].float(),
self.mlp1_bias.float(),
self.mlp2_bias.float(),
experts_per_token=self.experts_per_token,
num_experts=self.num_experts,
swiglu_limit=self.swiglu_limit,
)
t = t.view(batch_size, n_ctx, dim)
return x + t
class TransformerBlock(torch.nn.Module):
def __init__(
self,
config: ModelConfig,
layer_idx: int,
device: torch.device | None = None,
):
super().__init__()
self.layer_idx = layer_idx
self.attn = AttentionBlock(config, layer_idx, device)
self.mlp = MLPBlock(config, layer_idx, device)
def forward(self, x: torch.Tensor, cache: Cache | None = None) -> torch.Tensor:
x = self.attn(x, cache=cache)
x = self.mlp(x)
return x
class Transformer(torch.nn.Module):
def __init__(
self,
config: ModelConfig,
device: torch.device | None = None,
):
super().__init__()
self.config = config
self.embedding = torch.nn.Embedding(
config.vocab_size, config.hidden_size, device=device, dtype=torch.bfloat16
)
self.block = torch.nn.ModuleList(
[
TransformerBlock(config, layer_idx, device)
for layer_idx in range(config.num_hidden_layers)
]
)
self.norm = RMSNorm(config.hidden_size, device=device)
self.unembedding = torch.nn.Linear(
config.hidden_size,
config.vocab_size,
bias=False,
device=device,
dtype=torch.bfloat16,
)
def forward(self, x: torch.Tensor, caches: list[Cache] | None = None) -> torch.Tensor:
caches=caches or [None] * len(self.block)
with record_function("embedding"):
x = self.embedding(x)
for block, cache in zip(self.block, caches):
with record_function("block"):
x = block(x, cache=cache)
with record_function("norm_f"):
x = self.norm(x)
with record_function("unembedding"):
x = self.unembedding(x)
return x.float()
@staticmethod
def from_checkpoint(
path: str, config: ModelConfig | None = None, device: str | torch.device = "cuda",
) -> "Transformer":
if not isinstance(device, torch.device):
device = torch.device(device)
if config is None:
config_path = os.path.join(path, "config.json")
with open(config_path, "r") as f:
json_config = json.load(f)
config = ModelConfig(**json_config)
model = Transformer(config=config, device=device)
model.eval()
checkpoint = Checkpoint(path, device)
for name, param in model.named_parameters():
torch.cuda.empty_cache()
loaded_tensor = checkpoint.get(name)
if "mlp1" in name:
if "weight" in name:
loaded_tensor, scales = quantize_mx4(loaded_tensor.mT.contiguous())
_, block_index, _, _ = name.split(".")
model.block[int(block_index)].mlp.mlp1_weight_mx = scales
param.data.copy_(loaded_tensor.storage.data)
else:
param.data.copy_(loaded_tensor)
elif "mlp2_weight" in name:
loaded_tensor, scales = quantize_mx4(loaded_tensor.mT.contiguous())
_, block_index, _, _ = name.split(".")
model.block[int(block_index)].mlp.mlp2_weight_mx = scales
param.data.copy_(loaded_tensor.storage.data)
elif "gate" in name and loaded_tensor.ndim == 2:
loaded_tensor = loaded_tensor.mT.contiguous()
param.data.copy_(loaded_tensor)
else:
param.data.copy_(loaded_tensor)
# NOTE: Required to avoid OOM errors
torch.cuda.empty_cache()
return model
class TokenGenerator:
@torch.inference_mode()
def __init__(self, checkpoint: str, context: int, device: torch.device):
self.device = device
self.model = Transformer.from_checkpoint(checkpoint, device=self.device)
self.caches = [Cache(1, context, self.model.config.num_key_value_heads, device=self.device) for _ in range(len(self.model.block))]
self.input_token = torch.zeros(1, dtype=torch.int32, device=self.device)
# Fix shared memory issues by constraining optimization flags
if update_opt_flags_constraints is not None:
# Reduce num_stages to fit within hardware shared memory limits
# Your GPU has 101376 bytes but kernel needs 131072, so reduce num_stages
update_opt_flags_constraints({
"num_stages": 2, # Reduce from default 3-4 to 2
"block_m": 64, # Reduce block size to lower memory usage
"block_k": 64 # Reduce block size to lower memory usage
})
# warmup
self.model(self.input_token[None, :], caches=self.caches)
# capture for sampling
self.graph = torch.cuda.CUDAGraph()
with torch.cuda.graph(self.graph):
self.logits = self.model(self.input_token[None, :], caches=self.caches)[0]
@torch.inference_mode()
def generate(self,
prompt_tokens: list[int],
stop_tokens: list[int] | None = None,
temperature: float = 1.0,
max_tokens: int = 0,
return_logprobs: bool = False):
stop_tokens = stop_tokens or []
for cache in self.caches:
cache.reset()
prompt_tokens = torch.as_tensor(prompt_tokens, dtype=torch.int32, device=self.device)
self.model(prompt_tokens[None, :-1], self.caches)
predicted_token = prompt_tokens[-1]
num_generated_tokens = 0
while max_tokens == 0 or num_generated_tokens < max_tokens:
self.input_token[0] = predicted_token
self.graph.replay()
if temperature == 0.0:
predicted_token = torch.argmax(self.logits[-1, :], dim=-1).item()
else:
probs = torch.softmax(self.logits * (1.0 / temperature), dim=-1)
predicted_token = torch.multinomial(probs[-1, :], num_samples=1).item()
num_generated_tokens += 1
if return_logprobs:
logprobs = torch.log_softmax(self.logits[-1, :], dim=-1)
selected_logprobs = logprobs[predicted_token].item()
yield predicted_token, selected_logprobs
else:
yield predicted_token
if predicted_token in stop_tokens:
break
复制上面的文件,覆盖gpt_oss/triton/model.py文件,并重新运行
pip install -e .这样就可以重新运行下面的命令来开启对话了
python -m gpt_oss.chat gpt-oss-20b/original/如果替换没有起作用,也可以考虑直接替换虚拟环境中的对应文件,路径一般是 .venv/lib/python3.12/site-packages/gpt_oss/torch/model.py
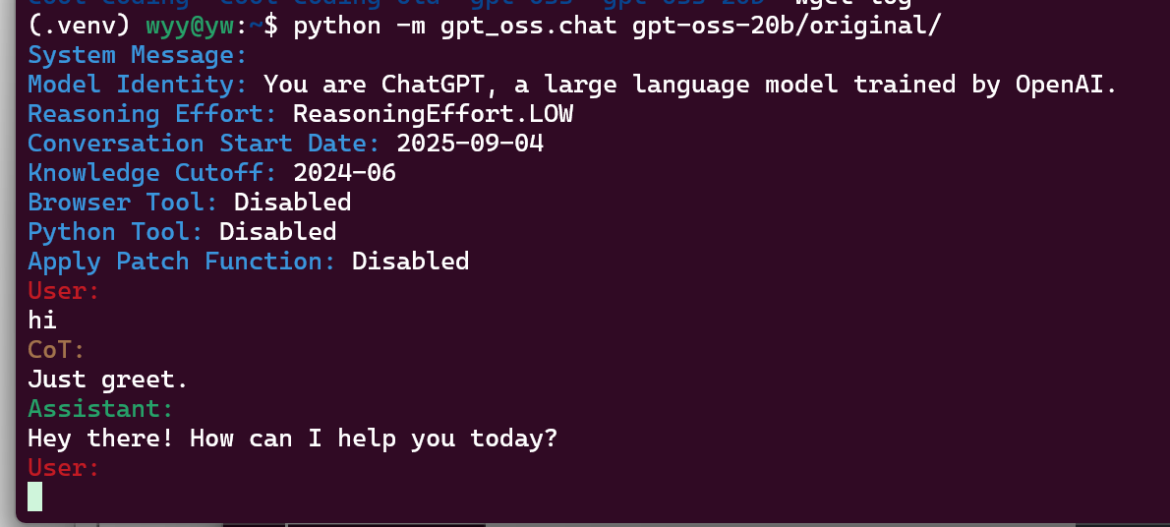
最终结果
发表回复